隨著數據量的爆炸式增長和業(yè)務需求的多樣化,分布式存儲系統(tǒng)在現代IT架構中扮演著至關重要的角色。curve作為一種高性能、高可靠的分布式存儲系統(tǒng),吸引了眾多開發(fā)者和企業(yè)的關注。本文將深入探討curve分布式存儲系統(tǒng)的軟件開發(fā)過程,涵蓋核心概念、架構設計、開發(fā)流程和最佳實踐,幫助讀者全面理解和掌握curve的開發(fā)與應用。
一、curve分布式存儲系統(tǒng)概述
curve是一個開源的分布式存儲系統(tǒng),旨在提供高效的數據存儲和管理解決方案。其核心設計理念包括高可用性、強一致性和水平擴展性。curve支持塊存儲和文件存儲,適用于云計算、大數據分析和容器化環(huán)境等場景。通過采用先進的算法和架構,curve能夠有效降低延遲、提高吞吐量,并確保數據的安全性和持久性。
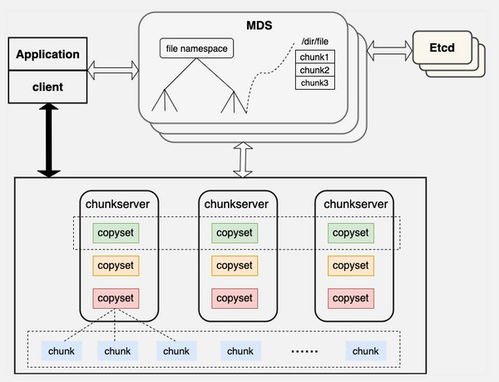
二、curve系統(tǒng)架構與核心組件
curve的架構主要包括以下關鍵組件:
- 元數據服務(Metadata Service):負責管理存儲系統(tǒng)的元數據,如文件目錄、塊映射等,確保數據的一致性和快速訪問。
- 數據存儲服務(Data Storage Service):處理實際數據的讀寫操作,采用分布式存儲機制將數據分散到多個節(jié)點,實現負載均衡和故障恢復。
- 客戶端SDK(Client SDK):為應用程序提供易用的API,支持多種編程語言,簡化集成過程。
- 監(jiān)控和管理模塊(Monitoring and Management):實時監(jiān)控系統(tǒng)狀態(tài),提供日志記錄、性能分析和自動化運維功能。
這些組件通過高效的通信協(xié)議協(xié)同工作,形成一個可靠的分布式存儲集群。開發(fā)者需要理解各組件間的交互方式,以便在開發(fā)過程中進行優(yōu)化和故障排查。
三、curve軟件開發(fā)流程
curve的軟件開發(fā)通常遵循以下步驟:
- 環(huán)境準備:安裝必要的依賴項,如C++編譯器、CMake構建工具和分布式系統(tǒng)庫。curve官方文檔提供了詳細的環(huán)境配置指南,建議使用Docker容器或虛擬機進行開發(fā)測試。
- 代碼獲取與編譯:從GitHub等平臺克隆curve源代碼,使用CMake編譯生成可執(zhí)行文件。開發(fā)者可以根據需求自定義編譯選項,例如啟用調試模式或優(yōu)化性能。
- 功能開發(fā)與測試:根據業(yè)務需求,添加新功能或修改現有模塊。curve采用單元測試和集成測試相結合的方式,確保代碼質量。建議使用模擬環(huán)境進行壓力測試,驗證系統(tǒng)在高負載下的穩(wěn)定性。
- 部署與運維:將開發(fā)完成的系統(tǒng)部署到生產環(huán)境,配置集群節(jié)點和網絡參數。curve提供了自動化部署工具,如Ansible腳本,簡化運維流程。
四、最佳實踐與常見挑戰(zhàn)
在curve軟件開發(fā)中,開發(fā)者應注意以下最佳實踐:
- 性能優(yōu)化:利用curve的緩存機制和并行處理能力,減少I/O延遲。例如,通過調整數據分片大小和副本策略,平衡存儲效率與可靠性。
- 容錯處理:設計健壯的錯誤處理機制,應對節(jié)點故障或網絡分區(qū)問題。curve內置了數據恢復功能,但開發(fā)者需確保應用程序能正確處理異常情況。
- 安全性與合規(guī)性:實施數據加密和訪問控制,保護敏感信息。curve支持TLS/SSL傳輸加密和基于角色的權限管理,建議結合企業(yè)安全策略進行配置。
常見挑戰(zhàn)包括分布式一致性的維護、大規(guī)模集群的管理以及與其他系統(tǒng)的集成。通過參與curve社區(qū)和參考案例研究,開發(fā)者可以快速解決這些問題。
五、總結與展望
curve分布式存儲系統(tǒng)以其靈活性和高性能,成為現代軟件開發(fā)的重要工具。通過掌握其架構和開發(fā)流程,開發(fā)者能夠構建可擴展的存儲解決方案,滿足日益增長的數據需求。未來,curve將繼續(xù)演進,融入AI驅動的優(yōu)化和邊緣計算支持,為分布式存儲領域帶來更多創(chuàng)新。鼓勵開發(fā)者積極參與開源貢獻,共同推動curve生態(tài)系統(tǒng)的發(fā)展。